Простые сбалансированные скобки¶
А теперь обратим наше внимание на использование стека при решении реальных задач в информатике. Например, когда вы пишете такое арифметическое выражение:
\((5+6)*(7+8)/(4+3)\)
у вас не возникает сомнений, где использовать скобки, чтобы задать порядок вычисления операций. Вы также можете иметь некоторый опыт программирования на языке вроде Лиспа с конструкциями наподобие
(defun square(n)
(* n n))
Здесь определена функция square, возвращающая квадрат аргумента n. Лисп вообще славится использованием огромного количества скобок.
В обоих примерах скобки должны появляться сбалансированным образом. Сбалансированность скобок означает, что каждый открывающий символ имеет соответствующий ему закрывающий, и пары скобок правильно вложены друг в друга. Рассмотрим несколько строк корректно сбалансированных скобок:
(()()()())
(((())))
(()((())()))
Сравним их со следующими, несбалансированными:
((((((())
()))
(()()(()
Способность различать, какие скобки сбалансированы корректно, а какие нет - важная часть распознавания структур во многих языках программирования.
Таким образом, задача заключается в создании алгоритма, читающего строку из скобок слева неправо и определяющего, являются ли они сбалансированными. Чтобы найти решение, нам нужно сделать важное наблюдение. Обрабатывая символы слева направо, чаще всего вы встретитесь с тем, что последняя открывающая скобка соответствует следующей закрывающей (см. рисунок 4). Так же обработка самого первого открывающего символа может откладываться, пока с ним не будет связан самый последний в строке. Закрывающие символы соотносятся с открывающими в порядке, обратном их появлению - изнутри наружу. Это явный признак того, что для решения данной задачи можно использовать стек.
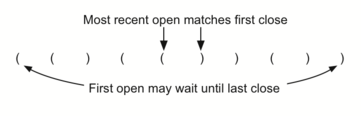
Рисунок 4: Связывание скобок
Как только вы соглашаетесь, что стек является подходящей структурой данных для хранения скобок, шаги алгоритма становятся очевидными. Начиная с пустого стека, строка скобок обрабатывается слева направо. Если символ - открывающая скобка, то она кладётся в стек, как напоминание, что соответствующий закрывающий знак должен появиться позже. С другой стороны, если символ - закрывающая скобка, то из стека выталкивается верхний элемент. До тех пор, пока будет происходить выталкивание для соотнесения каждого закрывающего символа, скобки будут сбалансированными. Если в какой-то момент в стеке не окажется открывающей скобки для связи с закрывающим символом, то строка является несбалансированной. В конце, когда будут обработаны все символы, стек должен быть пуст. Реализующий этот алгоритм код на Python показан в ActiveCode 4
Решение задачи балансирования скобок (parcheck1)
Данная функция, parChecker, предполагает доступность класса Stack и возвращает булев результат, сообщающий, сбалансирована ли строка. Обратите внимание, что булева переменная balanced инициализируется True, поскольку в начале у нас нет причин предполагать обратное. Если текущим символом является (, то она помещается в стек (строки 9-10). Заметьте, в строке 15 pop просто удаляет символ из стека. Возвращаемое значение не используется, поскольку мы знаем, что это должна быть открывающая скобка, встреченная ранее. В конце (строки 19-22), при условии, что выражение сбалансировано и стек абсолютно пуст, делается вывод, что входной параметр представляет из себя правильно сбалансированную последовательность скобок.