Словари¶
Второй основной структурой данных в Python является словарь. Как вы, наверное, помните, словари отличаются от списков тем, что в них вы получаете доступ к элементу по ключу, а не по позиции. Позднее в этой книге вы увидите множество способов реализации словаря. Сейчас же наиболее важно отметить, что операции получения и записи элемента в словарь имеют \(O(1)\). Другой важной операцией со словарями является определение принадлежности ему элемента. Проверка, есть ли с словаре данный ключ или нет, тоже \(O(1)\). Эффективности всех операций над словарями собраны в Таблице 3. Важное замечание в сторону относительно производительности словарей: эффективности, которые мы предоставляем в таблице, - это усреднённая производительность. В редких случаях принадлежность, получение или запись элемента могут деградировать до \(O(n)\). Мы встретимся с этим в одной из последующих глав, когда будем говорить о различных способах, которыми можно реализовать словарь.
| операция | эффективность |
|---|---|
| копирование | O(n) |
| получить элемент | O(1) |
| записать элемент | O(1) |
| удалить элемент | O(1) |
| вхождение (in) | O(1) |
| итерация | O(n) |
В нашем последнем эксперименте с производительностью мы сравним эффективность операций принадлежности у списков и словарей. В процессе мы подтвердим, что оператор принадлежности для списков имеет \(O(n)\), а для словарей - \(O(1)\). Производить сравнение мы будем просто. Мы создадим список с диапазоном чисел, затем будем брать число случайным образом и смотреть, есть ли оно в списке. Если наша таблица производительности верна, то чем больше список, тем дольше будет происходить определение, содержится ли в нём данное число.
Мы повторим тот же эксперимент со словарём, содержащим числа в качестве ключей. В этом эксперименте мы хотим увидеть, что определение есть или нет число в словаре не только намного быстрее, но и время, занимаемое для проверки, остаётся постоянным, даже если объём словаря возрастает.
Листинг 6 реализовывает это сравнение. Заметьте, что мы выполняем в точности одинаковые операции number in container. Различие только в том, что в седьмой строке <code>x</code> - это список, а в девятой - словарь.
Листинг 6
1 2 3 4 5 6 7 8 9 10 11 | import timeit
import random
for i in range(10000,1000001,20000):
t = timeit.Timer("random.randrange(%d) in x"%i,
"from __main__ import random,x")
x = list(range(i))
lst_time = t.timeit(number=1000)
x = {j:None for j in range(i)}
d_time = t.timeit(number=1000)
print("%d,%10.3f,%10.3f" % (i, lst_time, d_time))
|
Рисунок 4 подытоживает результаты запуска Листинге 6. Вы видите, что словарь стабильно быстрее. Для списков малых размеров на 10 000 элементов словарь быстрее в 89,4 раза. Для больших списков на 990 000 элементов разница становится в 11 603 раза! Вы также можете видеть, что время, требуемое операции проверки принадлежности для списка, линейно возрастает с ростом размера списка. Это подтверждает утверждение, что оператор принадлежности для списков имеет \(O(n)\). Так же хорошо видно, что аналогичная операция для словаря остаётся постоянной даже при возрастании объёма словаря. Фактически, для словаря размером в 10 000 операция проверки принадлежности занимает 0,004 миллисекунды, как и для словаря на 990 000 элементов.
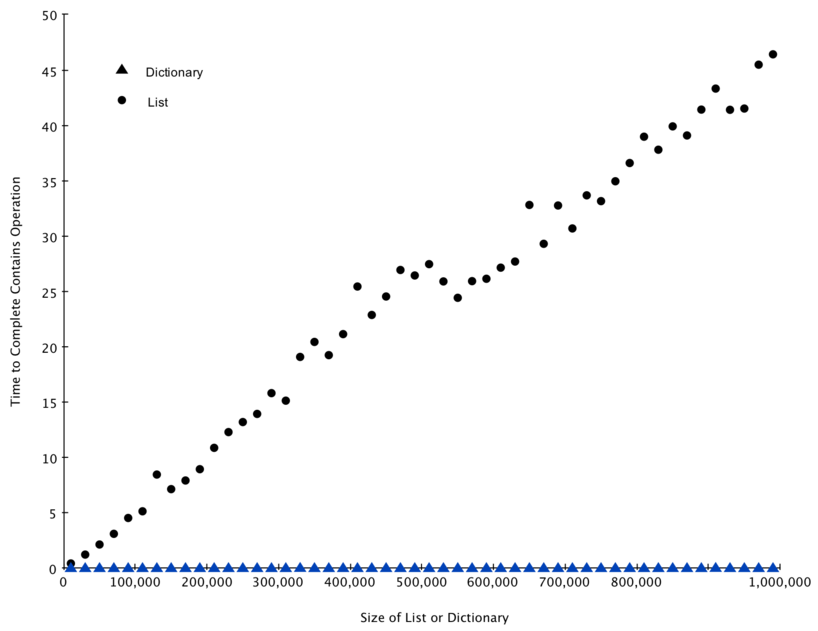
Рисунок 4: Сравнение операторов in для списков и словарей в Python
Поскольку Python - развивающийся язык, то за сценой постоянно происходят изменения. Последнюю информацию о производительности структур данных в Python можно найти на сайте Python. На момент написания этих строк Python wiki имеет хорошую страничку, посвящённую временной сложности. Вы можете ознакомиться с ней Time Complexity Wiki
Самопроверка