Приступая к работе с данными¶
Выше мы уже отмечали, что Python поддерживает парадигму объектно-ориентированного программирования. Это означает, что в фокус процесса решения задачи Python ставит данные. В Python, как и в любом другом объектно-ориентированном языке программирования, мы определяем класс, являющийся описанием того, как, собственно, выглядят данные (состояние) и что они могут делать (поведение). Классы аналогичны абстрактным типам данных, поскольку пользователь класса видит только состояние и поведение единицы данных. Такие единицы в объектно-ориентированной парадигме называются объектами. Объект является экземпляром класса.
Встроенные элементарные типы данных¶
Начнём наш обзор с рассмотрения элементарных типов данных. У Python есть два основных встроенных числовых класса, реализующих типы для целых чисел и чисел с плавающей запятой. Они называются int и float. Стандартные арифметические операции +, -, , / и * (возведение в степень) могут использоваться со скобками, задающими порядок операций, отличный от обусловленного обычным приоритетом операторов. Другими полезными операциями являются оператор остатка целочисленного деления % и собственно целочисленного деления //. Обратите внимание, что при делении двух целых чисел результат - число с плавающей запятой. Оператор целочисленного деления возвращает целую часть частного путём отсечения от неё дробной части.
Основные арифметические операторы (intro_1)
Логический тип данных, реализованный в Python как класс bool, будет весьма полезен для представления значений истинности. Возможными значениями для логического объекта являются True и False со стандартными булевыми операторами and, or и not.
>>> True
True
>>> False
False
>>> False or True
True
>>> not (False or True)
False
>>> True and True
True
Объекты булева типа данных также используются в качестве результатов операций сравнения, таких как “равно” (==) и “больше, чем” (\(>\)). Кроме того, операторы отношений и логических операций могут быть скомбинированы вместе в форме сложных логических вопросов. В Таблице 1 показаны операторы отношений и логические операторы вместе с примерами их использования.
| Название | Оператор | Описание |
|---|---|---|
| меньше | \(<\) | Оператор “меньше” |
| больше | \(>\) | Оператор “больше” |
| меньше или равно | \(<=\) | Оператор “меньше или равно” |
| больше или равно | \(>=\) | Оператор “больше или равно” |
| равно | \(==\) | Оператор равенства |
| не равно | \(!=\) | Оператор неравенства |
| логическое “и” | \(and\) | Если оба операнда истинны, то результат тоже истина |
| логическое “или” | \(or\) | Если хотя бы один из операндов истина, то результат - истина |
| логическое “не” | \(not\) | Инвертирует значение: False становится True и наоборот |
Основные логические операторы и операторы отношений (intro_2)
В качестве имён в языках программирования используются идентификаторы. В Python они начинаются с буквы или подчёркивания (_), чувствительны к регистру и могут быть произвольной длины. Не забывайте о том, что давать имена, отражающие смысл переменной, - всегда здравая идея, делающая ваш код более простым для чтения и понимания.
В Python переменная создаётся при первом использовании имени с левой стороны от оператора присваивания. Присваивание предоставляет возможность ассоциировать имя со значением. Переменная будет содержать ссылку на кусочек данных, а не сами данные. Рассмотрим следующий код:
>>> theSum = 0
>>> theSum
0
>>> theSum = theSum + 1
>>> theSum
1
>>> theSum = True
>>> theSum
True
Присваивание theSum = 0 создаёт переменную с именем theSum, содержащую ссылку на объект данных 0 (см. Рисунок 3). В целом, когда правая часть оператора присваивания вычисляется, ссылка на результат “назначается” имени в левой части. В данный момент в нашем примере тип переменной - целое, и это тип данных, на которые сейчас ссылается theSum. Если он изменится (см. Рисунок 4), как показано выше, на булево значение True, то изменится и тип переменной (сейчас theSum имеет тип bool). Оператор присваивания меняет ссылки, хранящиеся в переменной. Это динамическая характеристика Python. Одна и та же переменная может ссылаться на различные типы данных.

Рисунок 3: Переменная содержит ссылку на объект данных
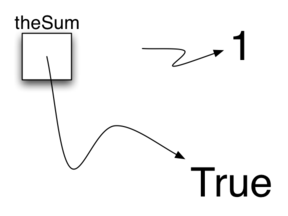
Рисунок 4: Присваивание изменяет ссылку
Встроенные составные типы данных¶
Кроме числовых и булева типов данных у Python есть несколько мощных встроенных составных классов. Списки, строки и кортежи являются упорядоченными коллекциями. Они весьма схожи по общей структуре, но имеют специфические различия, понимать которые необходимо для уместного их использования. К неупорядоченным коллекциям относятся множества и словари.
Список - это упорядоченная коллекция из нуля или более ссылок на объекты данных Python. Списки записываются как разделённые запятыми значения, заключённые в квадратные скобки. Пустой список выглядит просто []. Списки гетерогенны. Это означает, что их объекты не обязательно должны иметь один и тот же тип, и коллекция может быть присвоена переменной, как показано ниже. Следующий фрагмент показывает различные объекты данных Python, объединённые в список.
>>> [1,3,True,6.5]
[1, 3, True, 6.5]
>>> myList = [1,3,True,6.5]
>>> myList
[1, 3, True, 6.5]
Обратите внимание, что результатом вычисления списка в Python является он сам. Тем не менее, чтобы запомнить список для последующей обработки, ссылка на него должна быть присвоена переменной.
Поскольку списки считаются последовательно упорядоченными, то они поддерживают ряд операций, которые могут быть применены к любой Python-последовательности. Эти операции собраны в Таблице 2 вместе с примерами их использования.
| Имя оператора | Оператор | Пояснение |
|---|---|---|
| индексирование | [ ] | Доступ к элементу последовательности |
| конкантенация | + | Объединение двух последовательностей |
| повторение | * | Конкатенация повторений заданное количество раз |
| принадлежность элемента | in | Запрос о принадлежности элемента данной последовательности |
| длина | len | Запрос количества элементов в последовательности |
| срез | [ : ] | Выделение части последовательности |
Обратите внимание, что индексы элементов списка начинаются с 0. Операция среза myList[1:3] возвращает список элементов, начинающийся с элемента под индексом 1, но при этом не включает в себя элемент под индексом 3.
Иногда у вас может возникнуть желание проинициализировать список. Этого легко достичь, используя повторения. Например,
>>> myList = [0] * 6
>>> myList
[0, 0, 0, 0, 0, 0]
Одно важное отступление, касающееся оператора повторения: его результатом будет последовательность повторений ссылок на объект данных. Это хорошо видно в следующем примере:
Повторение ссылок (intro_3)
Переменная А содержит коллекцию из трёх ссылок на оригинальный список myList. Обратите внимание, что изменение одного элемента в myList отражается на всех трёх вхождениях в А.
Списки поддерживают ряд методов, которые будут использоваться для построения структур данных. В Таблице 3 представлено обобщение методов для работы со списками. Ниже идут примеры их применения.
| Название метода | Использование | Пояснение |
|---|---|---|
| append | alist.append(item) | Добавить новый элемент в конец списка |
| insert | alist.insert(i,item) | Вставить элемент в i-ую позицию списка |
| pop | alist.pop() | Удалить из списка и вернуть последний элемент |
| pop | alist.pop(i) | Удалить из списка и вернуть i-й элемент |
| sort | alist.sort() | Отсортировать список (изменяет оригинал) |
| reverse | alist.reverse() | Изменить список, чтобы элементы шли в обратном порядке |
| del | del alist[i] | Удалить элемент на i-й позиции |
| index | alist.index(item) | Вернуть индекс первого вхождения item |
| count | alist.count(item) | Вернуть число вхождений item в список |
| remove | alist.remove(item) | Удалить первое вхождения item |
Примеры методов для списков (intro_5)
Как вы можете видеть, некоторые методы (например, pop) возвращают значение и при этом модифицируют список. Другие (как reverse) просто изменяют список. По умолчанию pop применяется к концу списка, но может также удалять и возвращать конкретное значение. Для всех этих методов индексация по прежнему начинается с нуля. Вы также могли отметить знакомую “dot”-нотацию, запрашивающую у объекта вызов метода. myList.append(False) можно прочитать как “запросить у объекта myList выполнение его метода append и отправить через него значение False”. Даже такие простые объекты данных, как целые числа, могут вызывать свои методы подобным образом.
>>> (54).__add__(21)
75
>>>
В этом фрагменте мы просим объект целочисленного типа 54 выполнить его метод add (в Python называется __add__), передав в него 21, как число, которое нужно прибавить. Результатом будет сумма 75. Конечно, обычно мы это пишем как 54+21. Подробнее об этих методах мы поговорим чуть позже.
Ещё одной распространённой функцией, часто обсуждаемой в связке со списками, является функция range. Она производит объект “диапазон”, представляющий из себя последовательность значений. Используя функцию list, можно представить значение такого объекта в виде списка. Это проиллюстрировано ниже:
>>> range(10)
range(0, 10)
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(5,10)
range(5, 10)
>>> list(range(5,10))
[5, 6, 7, 8, 9]
>>> list(range(5,10,2))
[5, 7, 9]
>>> list(range(10,1,-1))
[10, 9, 8, 7, 6, 5, 4, 3, 2]
>>>
Объект “диапазон” представляет из себя последовательность целых чисел. По умолчанию он начинается с нуля. Если вы предоставите больше параметров, то он будет начинаться и заканчиваться в конкретных точках и сможет даже пропускать некоторые элементы. В нашем первом примере - range(10) - последовательность начинается с 0 и продолжается до 9 (не включая 10). Во втором примере - range(5,10) - начинается с 5 и заканчивается 9 (опять же, не включая 10). range(5,10,2) работает аналогично, но пропускает каждый второй элемент (10 по прежнему не включается).
Строки представляют собой коллекции с последовательным доступом из нуля или более букв, чисел и прочих знаков. Мы называем все эти элементы символами. Строковый литерал отличается от идентификатора использованием кавычек (одинарных или двойных).
>>> "David"
'David'
>>> myName = "David"
>>> myName[3]
'i'
>>> myName*2
'DavidDavid'
>>> len(myName)
5
>>>
Поскольку строки - это последовательности, то все описанные выше операции для последовательностей будут с ними работать так, как ожидается. Дополнительно у строк есть ещё несколько методов, некоторые из которых представлены в Таблице 4. Например,
>>> myName
'David'
>>> myName.upper()
'DAVID'
>>> myName.center(10)
' David '
>>> myName.find('v')
2
>>> myName.split('v')
['Da', 'id']
Из них очень полезным для обработки данных является метод split. Он принимает строку и возвращает список строк, используя расщепляющий символ как точку разделения. В нашем примере таковым является v. Если разделитель не указан, то split ищет пробельные символы (табуляции, переходы на новую строку и пробелы).
| Название метода | Использование | Пояснение |
|---|---|---|
| center | astring.center(w) | Возвращает строку, центрированную в поле размера w |
| count | astring.count(item) | Возвращает число вхождений item в строку |
| ljust | astring.ljust(w) | Возвращает строку с выравниванием по левому краю поля размером w |
| lower | astring.lower() | Возвращает строку из символов в нижнем регистре |
| rjust | astring.rjust(w) | Возвращает строку с выравниванием по правому краю поля размером w |
| find | astring.find(item) | Возвращает индекс первого вхождения item |
| split | astring.split(schar) | Разбивает строку на подстроки по символу schar |
Основное различие между списками и строками заключается в том, что списки можно изменять, а строки - нет. Это свойство называется мутабельностью. Списки мутабельны, строки иммутабельны. Например, вы легко можете изменить элемент списка, используя индексацию и присваивание. Для строк такие операции не допускаются.
>>> myList
[1, 3, True, 6.5]
>>> myList[0]=2**10
>>> myList
[1024, 3, True, 6.5]
>>>
>>> myName
'David'
>>> myName[0]='X'
Traceback (most recent call last):
File "<pyshell#84>", line 1, in -toplevel-
myName[0]='X'
TypeError: object doesn't support item assignment
>>>
Кортежи очень похожи на списки тем, что также являются гетерогенными последовательностями данных. Различие заключается в иммутабельности кортежей подобно строкам. Они не могут быть изменены. Кортежи записываются как разделённые запятыми значения, заключённые в круглые скобки. Будучи последовательностями, они могут использовать любые операции, описанные выше. Например:
>>> myTuple = (2,True,4.96)
>>> myTuple
(2, True, 4.96)
>>> len(myTuple)
3
>>> myTuple[0]
2
>>> myTuple * 3
(2, True, 4.96, 2, True, 4.96, 2, True, 4.96)
>>> myTuple[0:2]
(2, True)
>>>
Однако, если вы попытаетесь изменить элемент кортежа, то получите сообщение об ошибке. Обратите внимание, что такое сообщение содержит место и причину возникновения проблемы.
>>> myTuple[1]=False
Traceback (most recent call last):
File "<pyshell#137>", line 1, in -toplevel-
myTuple[1]=False
TypeError: object doesn't support item assignment
>>>
Множеством называется неупорядоченная коллекция из нуля или более неизменяемых объектов данных Python. Множества не допускают дубликатов и записываются как разделённые запятыми значения, заключённые в фигурные скобки. Пустое множество обозначается как set(). Множества гетерогенны и могут присваиваться переменным, как показано ниже.
>>> {3,6,"cat",4.5,False}
{False, 4.5, 3, 6, 'cat'}
>>> mySet = {3,6,"cat",4.5,False}
>>> mySet
{False, 4.5, 3, 6, 'cat'}
>>>
Не смотря на то, что множества не считаются последовательностями, они поддерживают некоторые знакомые операции из рассмотренных выше. Обзор таких операций представлен в Таблице 5, а дальнейший код демонстрирует примеры их использования.
| Название оператора | Оператор | Пояснение |
|---|---|---|
| membership | in | Принадлежность множеству |
| length | len | Возвращает количество элементов множества |
| | | aset | otherset | Возвращает новое множество, содержащее все элементы обоих множеств |
| & | aset & otherset | Возвращает новое множество из элементов, общих для обоих множеств |
| - | aset - otherset | Возвращает новое множество из элементов первого множества, не входящих во второе |
| <= | aset <= otherset | Спрашивает, все ли элементы первого множества входят во второе |
>>> mySet
{False, 4.5, 3, 6, 'cat'}
>>> len(mySet)
5
>>> False in mySet
True
>>> "dog" in mySet
False
>>>
Множества поддерживают некоторые операции, которые будут знакомы тем, кто работал с ними в математических областях. Обобщение по ним дано в Таблице 6, ниже идут примеры. Обратите внимание, что union, intersection, issubset и difference имеют специальные операторы, которые можно использовать вместо них.
| Название | Использование | Пояснение |
|---|---|---|
| union | aset.union(otherset) | Возвращает новое множество, состоящее из всех элементов обоих исходных множеств |
| intersection | aset.intersection(otherset) | Возвращает новое множество, состоящее только из элементов, общих для обоих исходных множеств |
| difference | aset.difference(otherset) | Возвращает новое множество, содержащее все элементы первого множества, не принадлежащие второму |
| issubset | aset.issubset(otherset) | Спрашивает, все ли элементы первого множества входят во второе |
| add | aset.add(item) | Добавляет новый элемент в множество |
| remove | aset.remove(item) | Удаляет элемент из множества |
| pop | aset.pop() | Удаляет произвольный элемент из множества |
| clear | aset.clear() | Удаляет все элементы из множества |
>>> mySet
{False, 4.5, 3, 6, 'cat'}
>>> yourSet = {99,3,100}
>>> mySet.union(yourSet)
{False, 4.5, 3, 100, 6, 'cat', 99}
>>> mySet | yourSet
{False, 4.5, 3, 100, 6, 'cat', 99}
>>> mySet.intersection(yourSet)
{3}
>>> mySet & yourSet
{3}
>>> mySet.difference(yourSet)
{False, 4.5, 6, 'cat'}
>>> mySet - yourSet
{False, 4.5, 6, 'cat'}
>>> {3,100}.issubset(yourSet)
True
>>> {3,100}<=yourSet
True
>>> mySet.add("house")
>>> mySet
{False, 4.5, 3, 6, 'house', 'cat'}
>>> mySet.remove(4.5)
>>> mySet
{False, 3, 6, 'house', 'cat'}
>>> mySet.pop()
False
>>> mySet
{3, 6, 'house', 'cat'}
>>> mySet.clear()
>>> mySet
set()
>>>
Заключительной из рассматриваемых нами коллекций Python будет неупорядоченная структура, называемая словарём. Словари - это коллекции ассоциированных пар элементов, каждая из которых состоит из ключа и значения. Эти пары обычно записываются как ключ:значение. Словари выглядят как разделённые запятыми пары ключ:значение, заключённые в фигурные скобки. Например,
>>> capitals = {'Iowa':'DesMoines','Wisconsin':'Madison'}
>>> capitals
{'Wisconsin': 'Madison', 'Iowa': 'DesMoines'}
>>>
Мы можем манипулировать словарём путём доступа к значению по его ключу или добавляя ещё одну пару ключ-значение. Синтаксис доступа выглядит очень похоже на аналогичный для последовательностей, за исключением того момента, что вместо индекса элемента, мы используем его ключ. Добавление новых элементов тоже похоже.
Использование Словарей (intro_7)
Тут очень важно обратить внимание, что словари не поддерживают какого-то определённого порядка для своих ключей. Первая добавленная пара ('Utah': 'SaltLakeCity') будет помещена на первое место в словаре, вторая ('California': 'Sacramento') - на последнее. Размещение ключей зависит от идеи “хеширования”, которая более детально будет объясняться в главе 4. Бонусом мы продемонстрировали, что функция для определения длины работает также, как и для предыдущих коллекций.
Словари имеют и методы, и операторы. Они расписаны в Таблице 7 и Таблице 8, а код ниже показывает их в действии. Методы keys, values и items возвращают объекты, содержащие интересующие нас значения. Вы можете использовать функцию list, чтобы конвертировать их в списки. Также показаны два варианта метода get. Если ключ не представлен в словаре, то get вернёт None. Однако, второй (опциональный) параметр может определять другое возвращаемое в этом случае значение.
| Оператор | Использование | Пояснение |
|---|---|---|
| [] | myDict[k] | Возвращает значение, ассоциированное с k, или ошибку, если такового не существует |
| in | key in adict | Возвращает True, если значение есть в словаре, False в противном случае |
| del | del adict[key] | Удаляет запись из словаря |
>>> phoneext={'david':1410,'brad':1137}
>>> phoneext
{'brad': 1137, 'david': 1410}
>>> phoneext.keys()
dict_keys(['brad', 'david'])
>>> list(phoneext.keys())
['brad', 'david']
>>> phoneext.values()
dict_values([1137, 1410])
>>> list(phoneext.values())
[1137, 1410]
>>> phoneext.items()
dict_items([('brad', 1137), ('david', 1410)])
>>> list(phoneext.items())
[('brad', 1137), ('david', 1410)]
>>> phoneext.get("kent")
>>> phoneext.get("kent","NO ENTRY")
'NO ENTRY'
>>>
| Метод | Использование | Пояснение |
|---|---|---|
| keys | adict.keys() | Возвращает ключи словаря как объект dict_keys |
| values | adict.values() | Возвращает значения словаря как объект dict_values |
| items | adict.items() | Возвращает пары ключ-значение как объект dict_items |
| get | adict.get(k) | Возвращает значение, ассоциированное с k, или None, если таковое не найдено |
| get | adict.get(k,alt) | Возвращает значение, ассоциированное с k, или alt, если такое не найдено |
Note
Данное рабочее пространство предоставлено для вашего удобства. Можете использовать это окно activecode для проб всего, что вам захочется.
(scratch_01_01)